
Motivation:
- Many powerful machine learning models, especially deep learning models, are complex and operate like black boxes. This makes it difficult to understand how they arrive at their decisions.
- Without interpretability, users can’t trust the model’s predictions. This is crucial in areas like finance, healthcare, autonomous driving, or criminal justice, where model decisions can have significant consequences


Interpretability and counterfactual explanations can help users understand the model’s reasoning and potentially challenge its decisions if necessary. This can improve user trust and acceptance of machine learning models.
Problem Statement:
The main aim of this work is finding the relevant feautres for a classifier that help it make its decision.

In the above figure (Fig 3), we can see, that just changing one feature changes its decision, which indicates that BMI is quite a relevant feature for Stroke prediction. In our project, we focus on getting such features but instead of tabular data, we aim for images.
In the image below (Fig. 4), in the first 2 images from the left, we can see when some changes in the dogs appearance like its shade and increased hair length are made, the dog breed classification predicts it as golden retriever instead of Chesapeake Bay , however, when it is made a bit short and smoother it predicts it as a Labrador. Such images generated are called Counterfactual explanations.

So if we define Counterfactual Explanation in a bit formal way:
For a given image that a classifier classifies as “c”, a Counterfactual Explanation would have a small change over I, so that now with the small change the classifier would classify it as some other class.
Counterfactual Explanation ≠ Adversarial Example:
- Counterfactual examples/Visual counterfacts need to be understandable, whereas adversarial examples mostly have noise invisible to the human eye.
- Counterfactual explanations seek to reveal the learned correlations related to the model’s decisions.
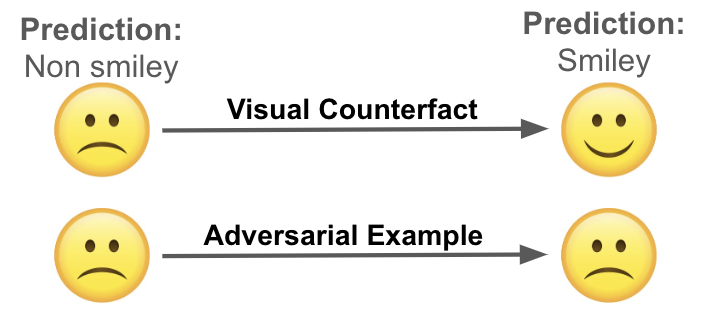
In the above image (Fig. 5), we can see that for a non smiley emoji, a CE would be a change in its lips, so that it gets predicted as a smiley emoji. However, an adversarial example would still look the same, but be predicted as smiley emoji.
Related Works:
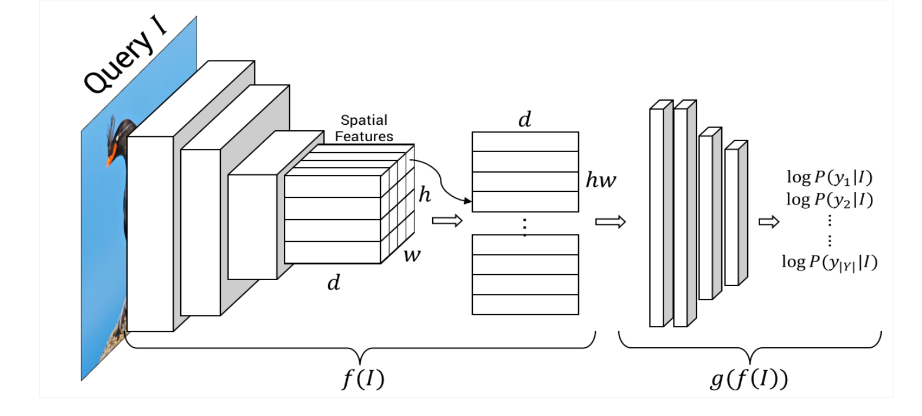
One approach [1], attempts to generate CE, using a feature extractor as seen in following image (Fig. 6), where it extracts features from an image of a given class and of an image from another class which we want our original image to be classified as. Then using multiple sampling strategies, the smaller chunks of the features latents are then swapped which are then fed to the classifier. They try to keep these swaps to a minimum and keep on swapping until the classifier’s prediction changes.
Limitations:
1. Requires image instances of the other class.
2. Limited by the features present in the other instance.
3. Requires multiple iterations for swapping features till the decision changes.
Diffusion:
To overcome some of these limitations, people started using Generative models to approach this problem of counteract generation. One of the leading generative method is diffusion. Diffusion models can not only generate from scratch but also modify a given image as desired [2,3]

In the above image (Fig. 7), we can see the model receives an image to which it adds noise step by step. It uses a conditioning variable to modify the images as desired. Here the conditioning can be from text, image, semantic maps, etc. Then it further removes this noise step by step in its reverse diffusion process, finally generates the desired image.
Diffusion Models for Counterfactual Generation:
Since diffusion models have a probabilistic nature it offers diverse set of images. This stochasticity also helps us get multiple explanations that may better describe a classifier’s error mode.
Thus here we can see a diffusion being used to generate a Counterfactual explanation in the following image (Fig. 8) as in [5]. In this image, we can see an input image of a non-smiling face and the aim is to modify it so that with small changes, it can be predicted as a smiling face. So in this approach, a diffusion model adds noise and denoises the image, where we can see a focused image for each diffusion step. In this, the unconditional DDPM diffusion generation is used, where the image that is being generated is modified based on 2 losses : 1. Loss from the classifier 2. A perceptual loss. The loss from the classifier is based on the other class that we want this image to be predicted as. The perceptual loss ensures that the generated image is as similar to the original image as possible to avoid extreme changes in the image.
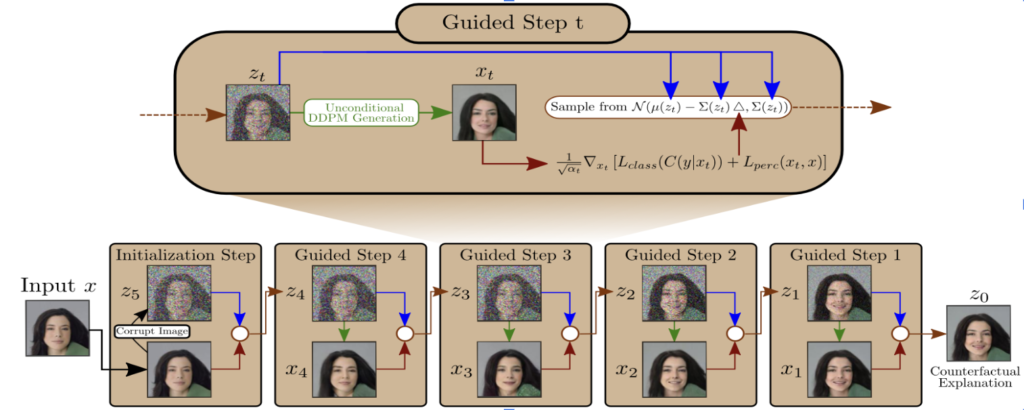
So at the end of the generation, we see an image which has its lips more in a smiley style, which helps it get classified as smiley face.
Limitations:
In all of the above work, there were no explicit steps taken to ensure that it doesn’t generate an adversarial example. Thus they are restricted to adversarially robust classifiers. Also, this whole process requires multiple iterations of the reverse process making it quite slow.
- Diffusion models generate good and diverse Counterfactual Explanations.
- We would be working on their efficiency as it requires multiple iterations of the reverse process to create one sample, making it a very slow process.
- We would also be working on building a method that need not rely on a robust model during the creation of CEs and still avoid generating adversarial examples. Thus enabling us to create CEs for any type of classifier model.
Our method using Diffusion for Counterfactual Explanation (CFE):
Changing description at different steps & onwards can have varying effects. Totally replacing a description i.e. a hard switch can have extreme effects. Instead, a soft combination can help transition smoothly and generate more aligned image.
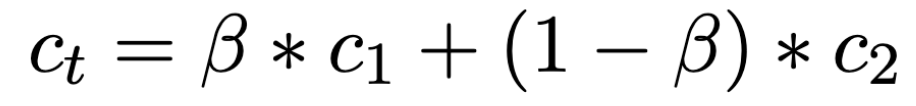
We can see in Fig 9, that changing description at different steps & onwards can have varying effects, where different prompts even when the diffusion process is being run with the same seed can generate very different images. Totally replacing a description i.e. a hard switch can have extreme effects. Instead a soft combination can help transition smoothly and generate more aligned image.[6]

Guiding conditions for our method:
1. Perceptual Similarity: To keep the generated image close to original image.
2. Classification change:: To guide the image to be classified as the desired class.
3. Adversarial Robustness: To avoid invisible changes that can change the classification.

Positive Results:

Negative Results:

Conclusion and Future Works:
References:
- Goyal, Y., Wu, Z., Ernst, J., Batra, D., Parikh, D., & Lee, S. (2019, May). Counterfactual visual explanations. In International Conference on Machine Learning (pp. 2376-2384). PMLR.
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in neural information processing systems, 33, 6840-6851
- Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
- Augustin, M., Boreiko, V., Croce, F., & Hein, M. (2022). Diffusion visual counterfactual explanations. Advances in Neural Information Processing Systems, 35, 364-377.
- Jeanneret, G., Simon, L., & Jurie, F. (2022). Diffusion models for counterfactual explanations. In Proceedings of the Asian Conference on Computer Vision (pp. 858-876).
- Wu, Q., Liu, Y., Zhao, H., Kale, A., Bui, T., Yu, T., … & Chang, S. (2023). Uncovering the disentanglement capability in text-to-image diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.