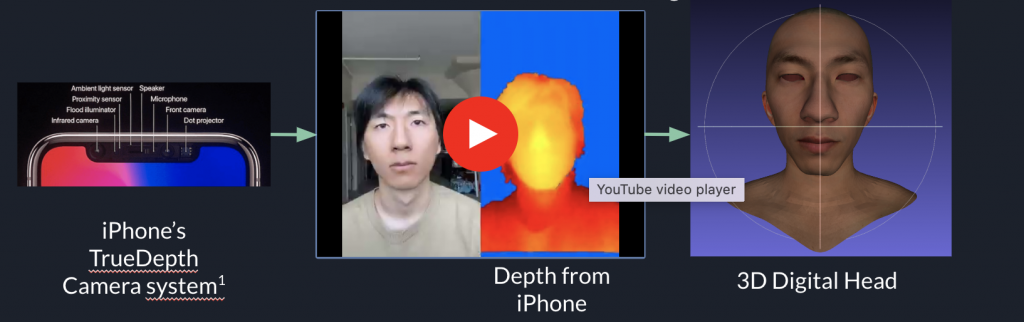
Neural Radiance Fields
Since its appearance in seminal work by Mildenhall et al., neural radiance fields[1] and its many follow-up works have shown great success in modeling 3D scene and provide an effective approach to 3D reconstruction and novel view synthesis. Compared to other types of scene representations (meshes, point clouds, volumes etc.), NeRF is more capable in capturing fine geometric details, which is crucial to creating realistic human model. With NeRF we are able to not only reconstruct the face and ears with more definition but also to include hairstyle in the model.
TensoRF
NeRF is limited in long training and rendering time. Since the seminal paper of original NeRF, a lot of work has been done to reduce reconstruction time as well as improve rendering quality. For the purpose of our project we based our experiments on one of the recent NeRF variation model, TensoRF[2]. TensoRF is able to achieve higher reconstruction quality in shorter training time compared to original NeRF model. The speed-up is obtained by standard PyTorch implementation, which provides a good foundation for our experiments.
Data
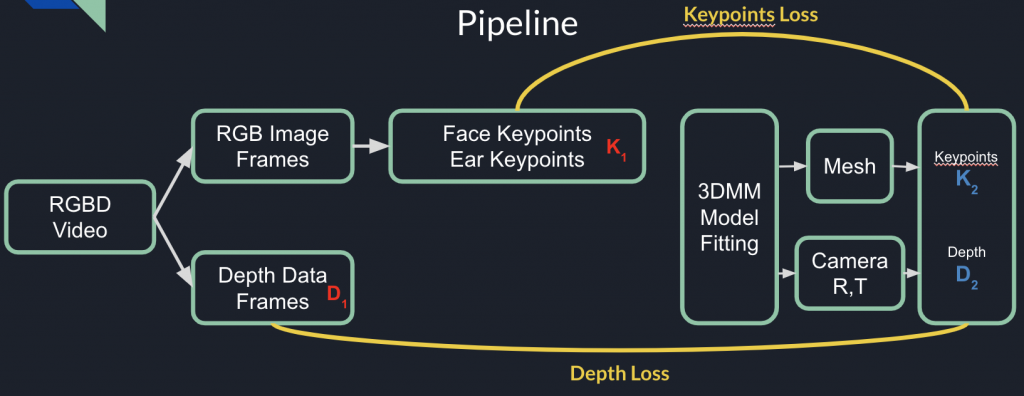
We use the IPhone 13 Pro to capture two types of data on multiple participants. In addition, since NeRF requires known camera pose for each frame to train, we use colmap3,4 to preprocess the RGB video and acquire a selection of critical frames and camera pose estimation.
- The participant uses our app to capture a selfie style video covering the two sides and front side of their face. This produces a ~30s RGB and depth video.

- The participant stands still while a second person takes a 360 degree video of the participant. This produces a ~30s RGB video.

Depth Supervision
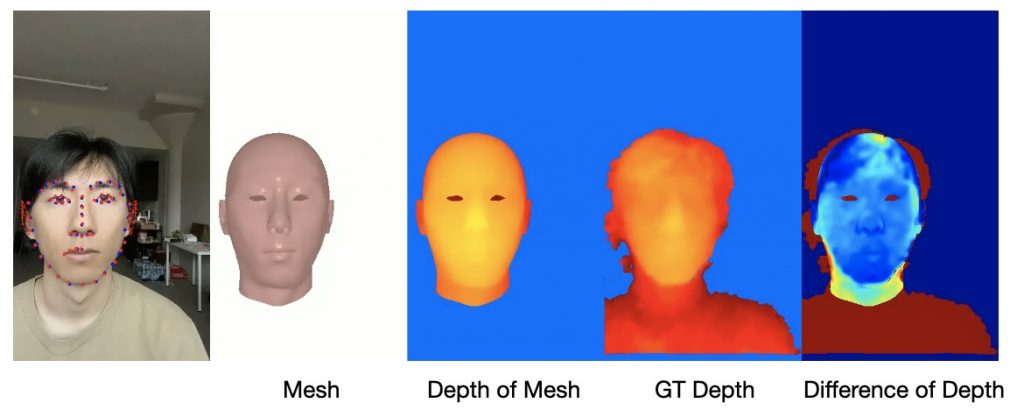
We utilize depth data to calculate a depth loss to help supervise NeRF training. This part of experiments are conducted with selfie style captured data. By conducting experiments with and without depth loss, we discover that adding depth loss helps with improving reconstruction quality. We use PSNR as a quantitative metric.
| Test PSNR | data 1 | data 2 | data 3 | data 4 |
| w/o depth | 17.94 | 16.24 | 13.08 | 14.91 |
| w depth | 18.14 | 16.67 | 13.56 | 15.14 |

We noticed that after adding depth supervision, there is a significant improvement in reconstructing the subject’s ears as shown in the visual result above.


We also noticed that adding depth loss helps with sharper visual result on the subject’s cheeks.
Front Face and Side Face Ratio
During experiments, we find that with selfie style captured data, there are more front face frames in the video sequence than side face. Front face frames also have higher quality than side face frames. Consciously adding more side face frames in the video frames in training NeRF result in better reconstruction quality.
| Test PSNR | data 1 | data 2 | data 3 |
| Original video | 18.14 | 16.67 | 13.56 |
| Adding side face frames | 18.26 | 17.75 | 15.45 |

Result
Finally we present visual results on 360 degree captured data. This type of data is captured by the IPhone back camera which has a higher resolution. With 360 degree it captures more complete view of the head and hair. Overall it achieves a better result on novel view synthesis of the head model.



References
- Mildenhall, Ben, et al. “Nerf: Representing scenes as neural radiance fields for view synthesis.” European conference on computer vision. Springer, Cham, 2020.
- A. Chen, Z. Xu, A. Geiger, J. Yu and H. Su. “TensoRF: Tensorial Radiance Fields.” ECCV. 2022.
- J.L. Schonberger, JM. Frahm. “Structure-from-Motion Revisited.” CVPR. 2016.
- J.L. Schonberger, E. Zheng, M. Pollefeys and JM. Frahm. “Pixelwise View Selection for Unstructured Multi-View Stereo.” ECCV. 2016.