
Abstract
Nowadays autonomous vehicles have an array of sensors. These sensors help detect the 3D shape of their surrounding environments and also help the vehicles navigate through them safely. This 3D information is also useful in other computer vision tasks like gesture recognition and geometric reconstruction. However every sensor has certain limitations. For instance, a RADAR or a LiDAR has excellent range information but provides poor spatial resolution whereas conventional cameras capture really high-quality spatial resolution but they fail to provide high range information. Our capstone thus aims at overcoming some of these limitations by fusing all these different sensors together. More precisely, we aim at fusing a Single Photon Lidar (SP-Lidar), a Stereo Pair and a LiDAR to form an intermediate cost volume which when passed through a deep neural network, estimates better disparity and depth information of the scene.
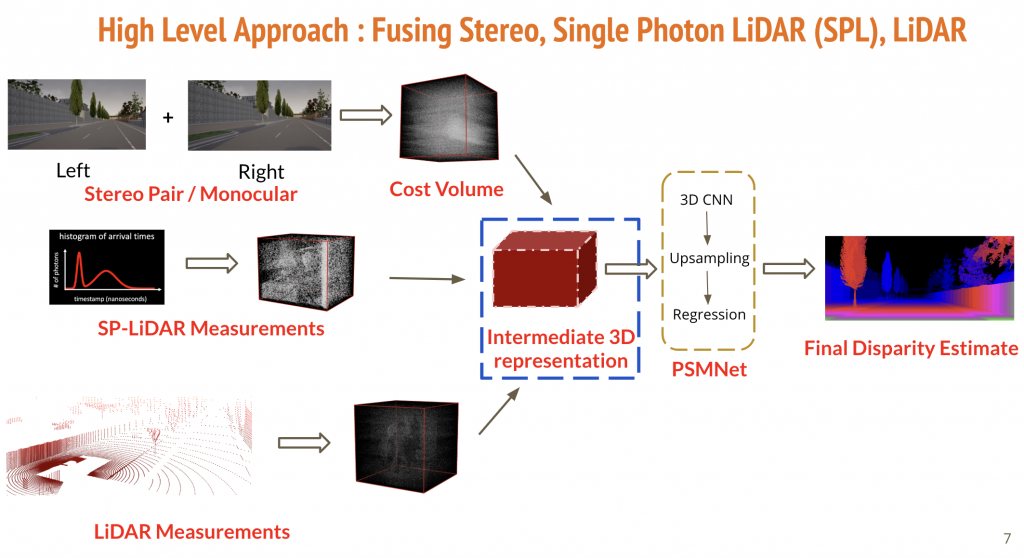
We start by first processing the stereo information using the Pyramid Stereo Matching Network (PSMNet)[1] which estimates disparity using a deep learning architecture. Broadly, PSMNet first generates an intermediate cost volume representation using Spatial Pyramid Pooling Layer and then uses a bunch of 3D convolutional layers to process this 3D volume. It finally upsamples the output and performs disparity regression.
We simulate our own dataset using CARLA [2] that has information from LiDAR, Single Photon LiDAR, Stereo and Monocular Cameras. In all we have around 8000 image pairs in training and 2000 images pairs in testing.
Since CARLA dataset doesn’t have SP-Lidar measurements, we simulate the same under various conditions. We assume that the data is coming from both the signal and the ambient photons and we apply Poisson noise to these photon counts. We explore the setting where Signal-to-Background (SBR) ratio is 1:1.
For our fusion technique, we first construct cost volumes for LiDARs, SP-LiDARs and Monocular Camera. We then normalize these individual cost volumes and simply add them to create an intermediate cost volume which then goes into the deep network, as has been depicted in the figure above.
We observe that fused features give the best performance for various metrics, under severe ambient conditions as well. We also test our model on the KITTI dataset [3] and showcase the generalization of our architecture over real world images as well. The future extension for this work can be to collect real world dataset for Single Photon LiDARs and test sensor calibration, time synchronisation problems etc. We can also try to incorporate other sensors such as RADARs in our sensor fusion pipeline.