Abstract
Autonomous driving presents one of the largest
problems that the robotics and artificial intelligence communities
are facing at the moment, both in terms of difficulty
and potential societal impact. Self-driving vehicles (SDVs) are
expected to prevent road accidents and save millions of lives
while improving the livelihood and life quality of many more.
However, despite large interest and several companies working in the autonomous domain, there is still more
to be done to develop a system capable of operating
at a level comparable to the best human drivers. One reason for
this is high uncertainty of traffic behavior and a large number of
situations that an SDV may encounter on the roads, making it
very difficult to create a fully generalizable system. To ensure
safe and efficient operations, an autonomous vehicle is required
to account for this uncertainty and to anticipate a multitude of
possible behaviors of traffic actors in its surrounding.
In this project, we discuss an important topic and address one of the crucial aspects, the problem of predicting the future state of an SDV’s surroundings for safe and efficient operations. We are working with Prof. Jeff Schneider to develop deep-learning-based approaches that take into account the current world state to infer future movement of actors (vehicles, pedestrians, bicyclists).
Detailed Information
Part (a): Vulnerable Road Users
Vulnerable Road Users (VRUs) are traffic actors with an increased risk of injury, generally unprotected by an outside shield. The two main actor classes under VRUs are pedestrians and bicyclists. We focus our ideas on pedestrians, as they account for a much larger proportion of the VRUs. We set up baselines on the BIWI and UCY datasets using several approaches. In particular, we experiment with Social-LSTM, Social-GAN, and LVA-LSTM.
Social-LSTM takes into account neighborhood interactions through a social pooling layer. Social-GAN extends the idea of Social-LSTM by adding scene level interactions, using a GAN to emulate more natural trajectories and using a Variety Loss to help predict the best of multiple sampled trajectories. LVA-LSTM encodes velocity information along with locations and uses attention to model the future velocities and locations of the pedestrians.
More information on the models can be seen in the final presentation slides.

Part (b): Vehicles
Vehicles make up for the largest proportion of all actors for an SDV. Towards this, we set up a baseline on the KITTI autonomous dataset using several approaches. In particular, we experiment with two state-of-art models, namely, DESIRE-SI and INFER-Skip which are stochastic and deterministic respectively.
DESIRE-SI combines the information of agent interactions, scene context, and velocity to provide a very detailed context for predictions. To predict multi-modal paths, it uses a Conditional Variational Auto-Encoder and uses Inverse Optimal Control to course-correct its predictions. INFER, on the other hand, builds intermediate representations and uses ConvLSTMs to predict the future state of actors as heatmaps.
More information on the models can be seen in the final presentation slides.

Argoverse
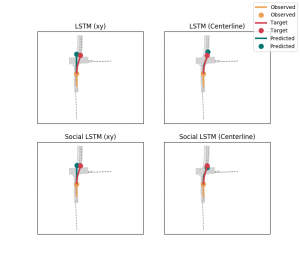
Argoverse is a recently released dataset by Argo AI. We focus on modeling the trajectories in both regular (xy) coordinates and also in the centerline (nt) coordinates, as specified for the AGENT class. We work in two directions – recurrent and feedforward.
Part (a): Recurrent Modeling
Here we focus on two models: Vanilla LSTM encoder-decoders and Social-LSTM — which does social pooling similar to Social-GAN mentioned above.
Part (a): Feedforward Modeling
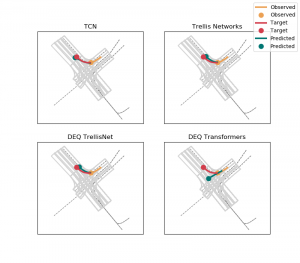
Inspired by recent work on feedforward sequential modeling in the Language domain, we work on recent architectures such as Temporal Convolutional Networks (TCN), Trellis Networks (weight-tied, input-injected TCNs) and Deep Equilibrium Models (root-finding for optimizing weight-tied networks towards an equilibrium point using implicit differentiation of Quasi-Newton methods).