
Abstract
We proposed a novel instance-based Neural Network Compression Method. Given the computational budget, e.g. the number of layers we can use for inference, our model predicts accurate labels while doesn’t exceed the budget. We conducted experiments on Cifar-10 and our approach prunes 30% layers and performs as same as using all layers.
Introduction
- Dynamic Layer Pruning
For different input sample, use different strategies to prune layers for acceleration.

Here is an example. We picked 5 different images from CIFAR-10 dataset and calculated the corresponding activation maps after the 17th layer. As we can see, for some images (Image 2, Image 4), their activations are close to zero, which means pruning 17th layer won’t affect much on accuracies on these images.
By doing an instance-based layer pruning, we have more flexibilities to prune different layers for different input images.
- Computational Budget
This means our model needs to make accurate predictions while not exceeding a fixed budget on the number of layers.
In many real worlds applications, it’s common that we have a changing computational budget. It would be useful if we have a tunable model so that it can control the trade-off between run-time and accuracy.
Method
- Architecture
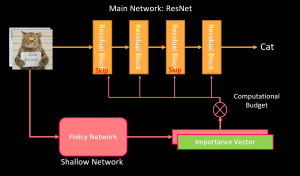 There are two parts in our network: the main network, and the policy network. The main network has many layers. Its input is an RGB image and its output is the predicted label. The policy network is a shallow ConvNet. At test time, the policy network takes a look at the input images and then output an importance vector indicating which layers in the main network are important for that specific input image. Given the computation budget, then we select the most important layers for prediction.
There are two parts in our network: the main network, and the policy network. The main network has many layers. Its input is an RGB image and its output is the predicted label. The policy network is a shallow ConvNet. At test time, the policy network takes a look at the input images and then output an importance vector indicating which layers in the main network are important for that specific input image. Given the computation budget, then we select the most important layers for prediction.
- Imitation Learning
The policy network is trained by imitation learning.
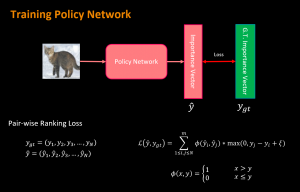
Agent: Policy Network
Expert: Optimal Important vector
Noted that the optimal important vectors are obtained by brute-force greedy search.
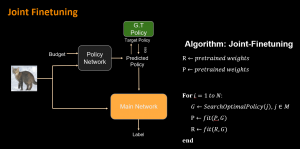
- Joint finetune
The parameters in the main network also need to be fine-tuned. The main reason is that our main network is pre-trained using all the layers instead of pruning propose. Therefore, by joint finetuning, we train the main network in a layer skipping scenario, which helps reduce the interdependencies among layers.
Experiments
Several experiments are conducted to evaluate our methods in terms of performance, efficiency, and flexibility. These experiments are done with Cifar-10 datasets and Mini-ImageNet dataset.
- Fixed Budget
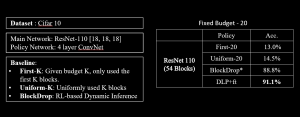
When the budget is fixed to 20, which is only using 20 out of 54 residual blocks. Our method (DLP) is better than the Reinforcement Learning based dynamic pruning method (BlockDrop).
- Comparison with BlockDrop
We also did a head-to-head comparison between BlockDrop and out approach.
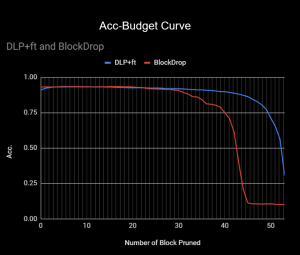
Our method works method when the computation is very limited. Noted that even if we pruned 90% of the layers, it can still achieve 77% of test accuracy.
- Compared to ResNet-110
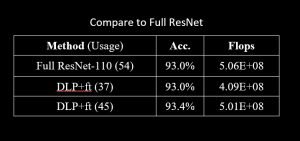
Using fewer Flops, our method has the same performance as ResNet-110. It can also use more computation to get an even higher test accuracy.
- Mini-ImageNet
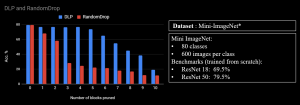 On mini-Imagenet, our method also performs much better than random layer pruning.
On mini-Imagenet, our method also performs much better than random layer pruning.
Conclusion
In this project, we proposed a new strategy for layer pruning. First, we search for the optimal pruning policy for each instance. We then use a policy network to learn the optimal policies. At test-time, we use the trained policy network to determine the best pruning policy.
This strategy can also be applied to resolution pruning, channel pruning. We can brute-force-search the optimal input resolution and optimal channel pruning strategies. And then use a network to learn them.
Acknowledgment
Great thanks to our supervisor Prof. Kris Kitani who gave invaluable suggestions and comments throughout this project. We also thank Amazon Lab 126 for constantly providing support.