

Datasets
As mentioned earlier, there is no well-defined work zone targeted data available and gaining access to work-zone relevant data to train the models has been the main focus of our efforts. This can be achieved in two ways:
- Approach 1: Exploring existing datasets and models trained on them with at least a sub set of the classes we are interested in.
- Approach 2: Collecting our own new data and annotating it.
- Approach 3: Augment the data to generate more data.
Approach 1: Explore Existing Datasets
As part of the early efforts in this project, we tried exploring existing datasets which had some representation for what we considered as “relevant” in the context of work-zones.
They include the following datasets:
- ACID
- Roadbotics
- LVIS
- NuScenes
- Argoverse 2.0
LVIS Dataset
We explored the Large Vocabulary Instance Segmentation (LVIS) Dataset which is a long tailed dataset with a couple relevant classes to construction zones:

We found 25 relevant classes as mentioned below.
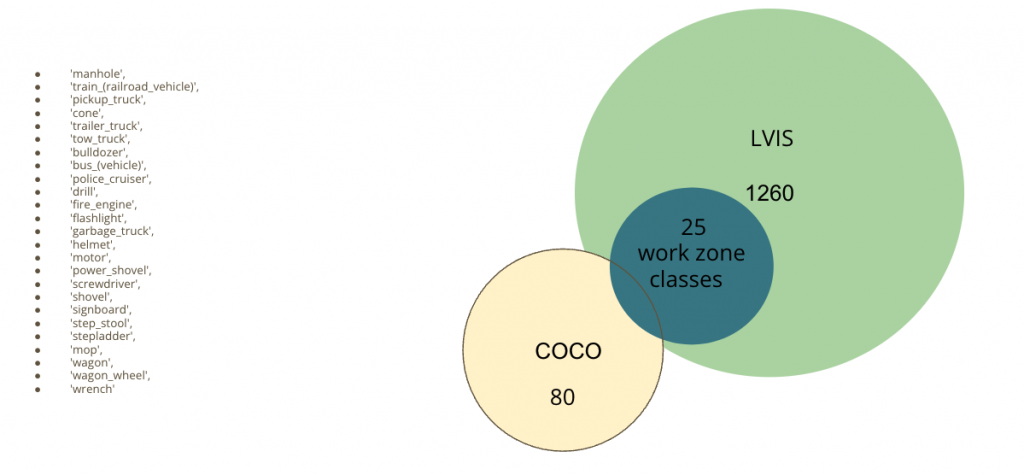
We incorporated LVIS Detection along with COCO Detections already running on static cameras installed at Pittsburgh Intersections and are currently investigating the data. Any time a class from these 25 seemingly relevant classes are detected, we go ahead and sample those video frames to check if there are construction zones.
NuScenes Dataset
LVIS has some relevant classes but misses out on two of the most important classes: Construction Workers and Heavy Machines. NuScenes has these two classes and some other construction zone relevant classes. We found 5 classes of relevance and are exploring those.
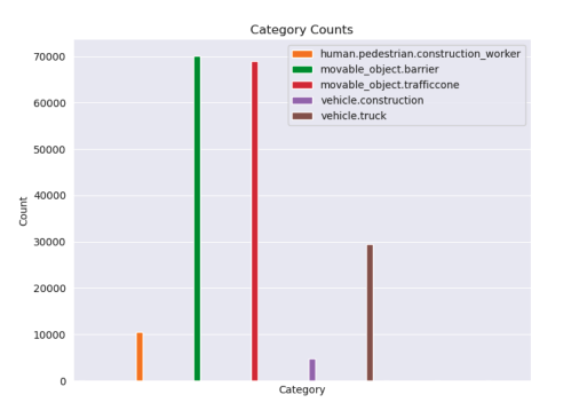
We the trained a NuScenes-Construction Object Detector which is trained on only these 5 classes and can help us detect construction zones with better confidence.
Argoverse 2.0
We also explored the recently released Argoverse 2.0 – Sensor Dataset for any construction zone relevant classes. We found a couple relevant classes.
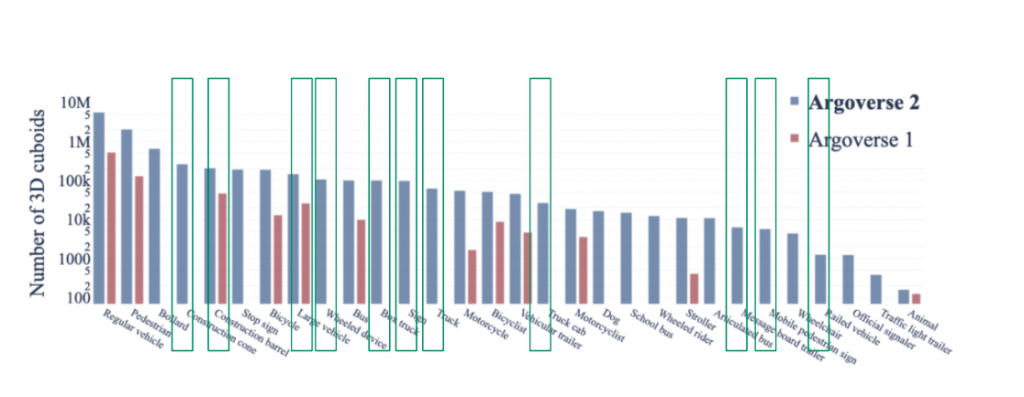
This way, we tried training our Faster R-CNN detection network using these datasets to be able to at least identify those image frames with some work-zone relevant classes.
The training and testing pipeline for this approach, looked as follows:
Training Pipeline
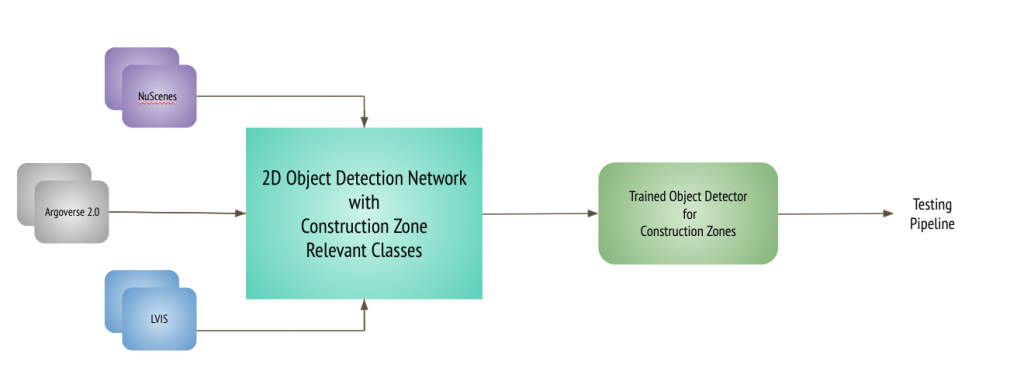
Testing Pipeline

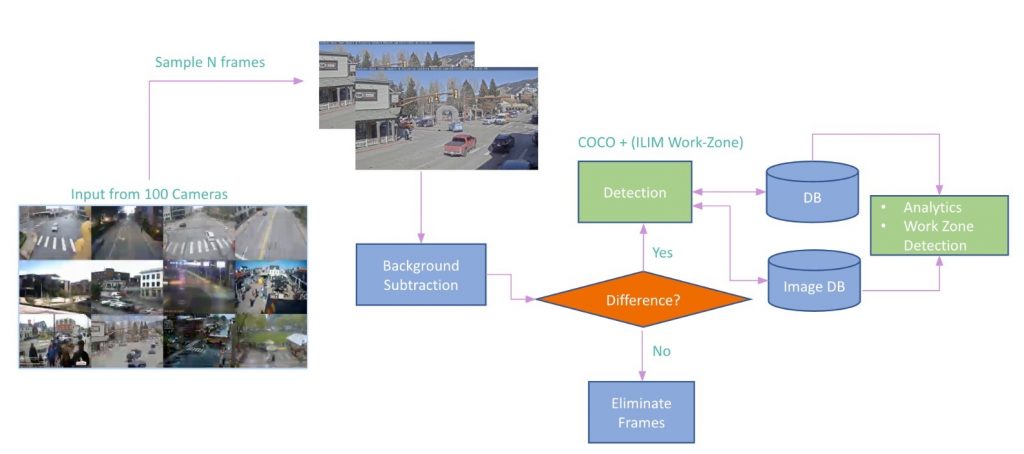
We feed in surveillance videos captured by the cameras at intersections. Sample 120 frames every 10 minutes, perform median subtraction and if we do find difference, we perform detection for COCO and the selected ‘work-zone’ relevant LVIS, NuScenes and ArgoVerse 2.0 classes and then perform further analysis on top of the detection results to finally pick frames that contain work-zone scenes in them.
Approach 2: Collect and Annotate to Generate a new Dataset
Post incorporating existing datasets and analyzing performance for construction zone relevant categories, it was realized that more construction zone relevant categories with more data per category were required for successfully calling out construction zones. The main reason being, the existing datasets are long-tailed and not targeted towards the task of construction zone detection and hence lack variety and enough work-zone relevant class representation in them. Therefore ILIM Lab at CMU undertook a data collection and annotation effort to get object bounding boxes and segmentation masks for 33 construction zone relevant object categories. The effort resulted in total of 2885 images, 30202 annotations and 33 categories. The statistics are depicted below.
PS: The annotation effort is ongoing and we expect to get access to more data in due course.

Revised Training Pipeline
Image segmentation annotations were acquired from the data annotation effort. The training pipeline was augmented to predict segmentation masks using fine-tuning of MaskRCNN. The detection-cum-segmentation results were utilized to perform probabilistic analysis for presence of construction zones.
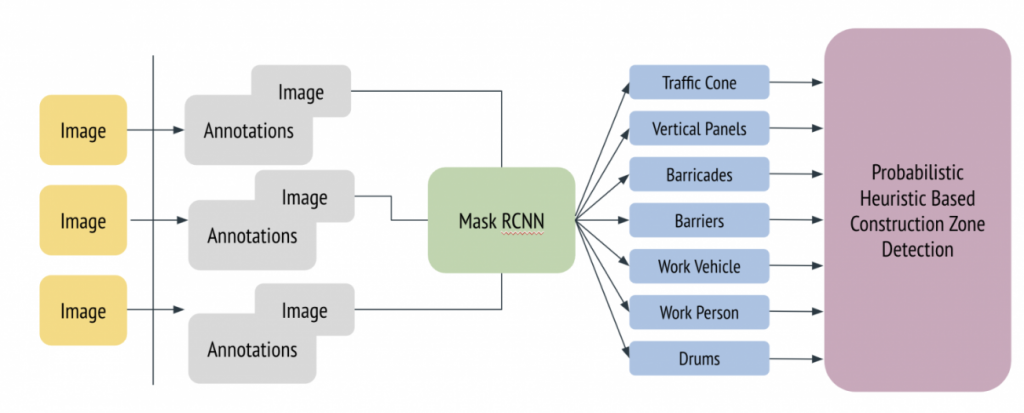
Approach 3: Augment Data
In an effort to add more data to the pipeline, 2D and 3D data annotation methods are explored.
2D Clip-And-Paste Data Augmentation
For 2D augmentations, cutting and pasting technique was used on 4 inter-changeable categories – Cones, drums, vertical panels and TTC message boards. They are similar in respect to the their aspect ratios and hence were randomly swapped with each other in the training dataset to augment and boost data in these 4 categories.

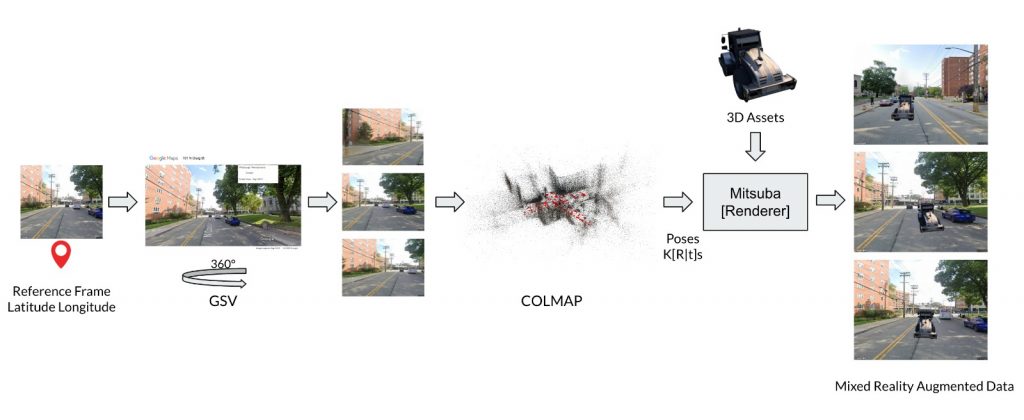
Mixed-Reality based 3D Synthetic Data Augmentation
We collected work-zone relevant 3D assets like JCB, cones etc. and performed a mixed reality based 3D-Synthetic data augmentation using SfM. We use a base image we intend to augment and query Google Street View API to get access to Street View images in its vicinity and perform sparse view reconstruction of the scene. Using the relative pose information between the cameras, we then compute the respective transforms and render the 3D asset from realistic view points and there by generate geometrically consistent multi-view synthetic data with precise 2D masks and annotations. The main limitation with this approach was to get access to enough work-zone relevant 3D assets.
The testing pipeline used was similar to the previous setup.
References:
[1] “WALT: Watch And Learn 2D Amodal Representation using Time-lapse Imagery”, N. Dinesh Reddy, Robert Tamburo, and Srinivasa Narasimha IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2022.